What Is a Robots.txt File
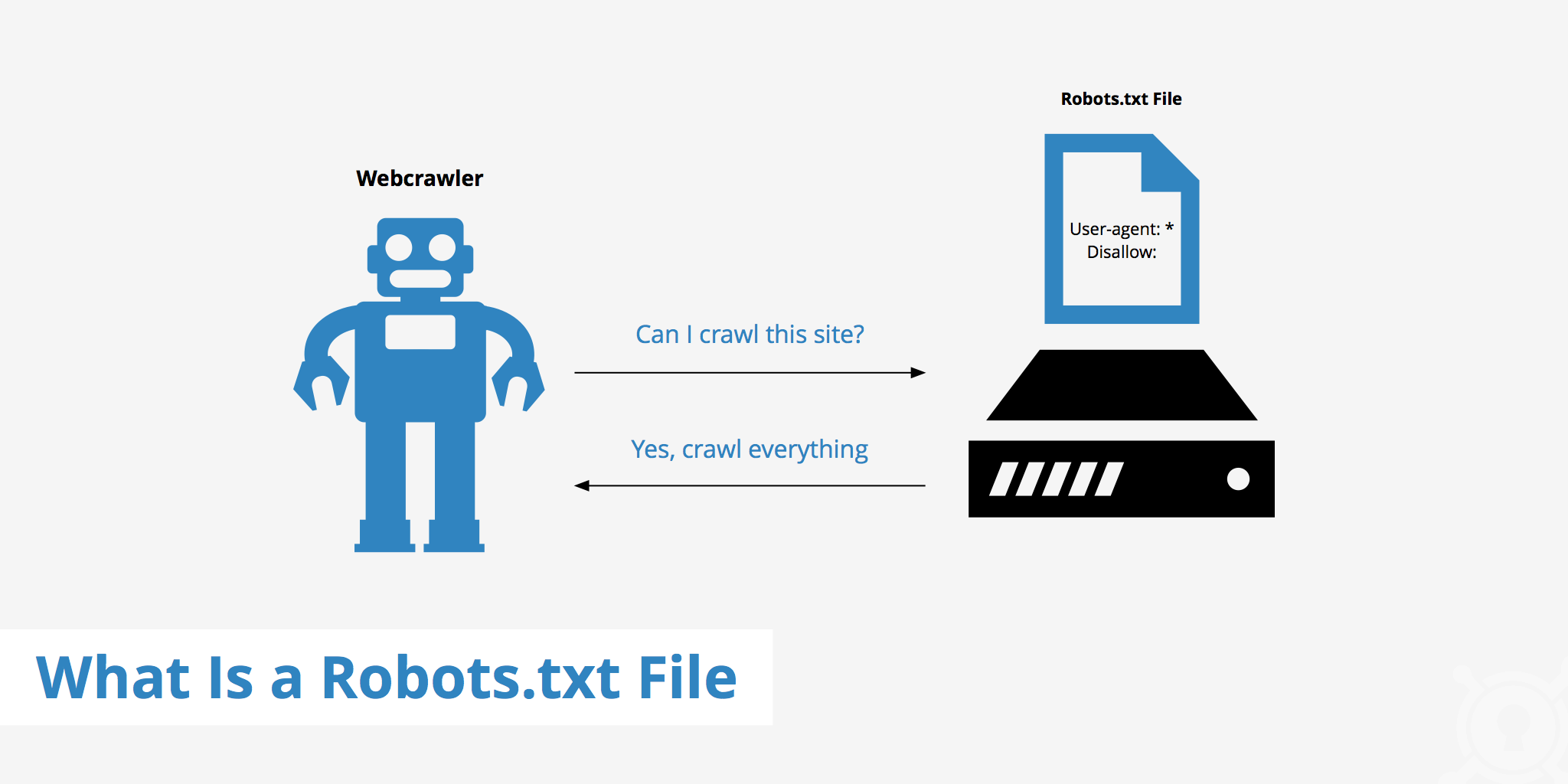
A robots.txt file provides search engines with the necessary information to properly crawl and index a website. Search engines such as Google, Bing, Yahoo, etc all have bots that crawl websites on a periodic basis in order to collect existing and/or new information such as web pages, blog articles, images, etc. Once these resources are published via the website it is up to the search engines to determine what will be indexed.
A robots.txt file can help you better define what you want the search bots to crawl and therefore index. Doing this is useful for a variety of reasons including controlling crawl traffic to help ensure that the crawler does not overwhelm your server. The robots.txt file however, should not be used to hide web pages from Google search results.
How to create a robots.txt file
Implementing the use of a robots.txt file is really quite simple and can be done in just a few steps.
- The first step is to actually create your robots.txt file. This can be achieved by creating a file called "robots.txt" with a simple text editor.
- Next, define your parameters within the robots.txt file. Example use cases have been outlined in the next section.
- Upload your robots.txt file to your website's root directory. Now whenever a search engine crawls your site, it will check your robots.txt file first to determine if there are sections of the website which shouldn't be crawled.
Robots.txt examples
There are a variety of possibilities available when configuring a robots.txt file. The basic structure of a robots.txt file is quite simple and often contains primary components such as User-agent, Disallow, or Allow. The User-agent specifies which search engine robots the following rules apply to. This field can be defined as User-agent: * to apply to all robots while a specific robot can also be specified such as User-agent: Googlebot.
Additionally, you can also use the Disallow and Allow directives to enable greater configuration granularity. The following outlines a few general configurations.
Example 1
This example instructs all search engine robots to not index any of the website's content. This is defined by disallowing the root / of your website.
User-agent: *
Disallow: /
Example 2
This example achieves the opposite of the previous one. In this case, the directives are still applied to all user agents, however there is nothing defined within the Disallow directive, meaning that everything can be indexed.
User-agent: *
Disallow:
Example 3
This example displays a little more granularity pertaining to the directives defined. Here, the directives are only relevant to Googlebot. More specifically, it is telling Google not to index a specific page: your-page.html
User-agent: Googlebot
Disallow: /your-page.html
Example 4
This example uses both the Disallow and Allow directives. The directory images is disallowed to be indexed by all search bots however, by defining Allow: /images/logo.png, we can override the Disallow directive for a particular file, in this case logo.png.
User-agent: *
Disallow: /images
Allow: /images/logo.png
Example 5
The final example is a use-case where JS, CSS, PNG files within the demo directory are allowed to be indexed by the web crawler, while all other files are not. The * before the filetype extension indicates that all files with this extension are allowed.
User-agent: *
Allow: /demo/*.js
Allow: /demo/*.css
Allow: /demo/*.png
Disallow: /demo/
Using a robots.txt file with a CDN
If you're using a CDN, you may also have the ability to define directives for the CDN's robots.txt file. KeyCDN doesn't enable the robots.txt file by default meaning that everything will be crawled. You can however choose to enable the robots.txt file in the Zone settings within the KeyCDN dashboard. Once the robots.txt file is enabled in KeyCDN, its default is set to:
User-agent: *
Disallow: /
However, this can be modified by adding custom directives to the custom robots.txt box. Once changes here are made, be sure to save your settings and purge your Zone.
For an in-depth guide to CDN SEO read our Indexing Images in SERPs article.
Summary
There are many reasons for having a robots.txt file including:
- You don't want search bots to index particular content,
- Your site isn't live yet,
- You want to specify which search bots can index content, etc.
However, it is not always necessary to have a robots.txt file. If you do not want to instruct search bots on how to crawl your website, you simply do not need a robots.txt file. Alternatively, in the case that you do, simply adding the file to the site's root directory and accessing it via https://example.com/robots.txt will allow you to easily customize how web crawlers will scan your site.
Be aware that when creating a robots.txt file you are not blocking any resources that the search bots need in order to properly index your content.
To help verify this, Google Search Console provides a robots.txt tester which you can use to verify that your robots file is not blocking any important content.