Load Balancing
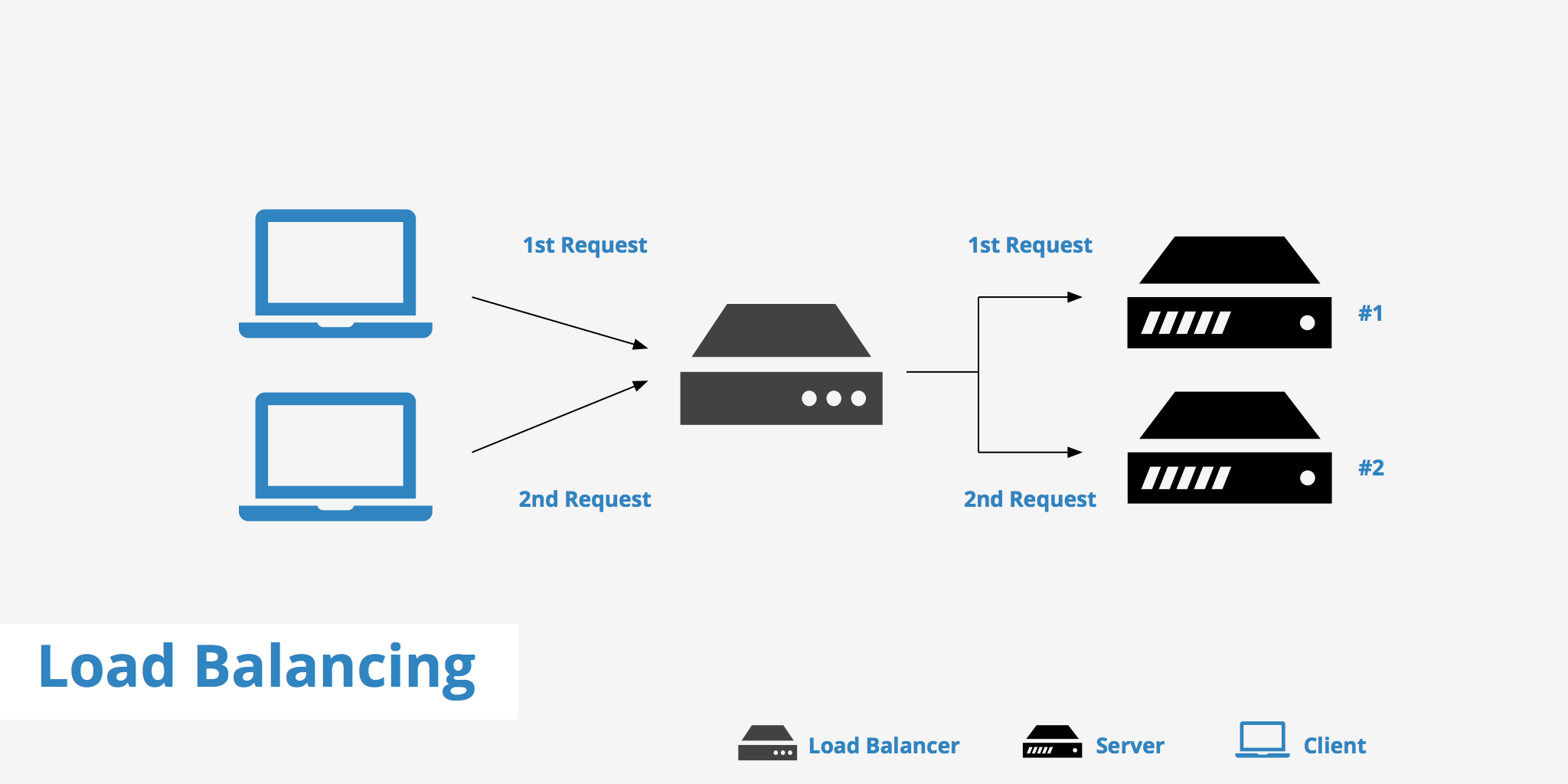
If you're running a website or an application that receives a high volume of traffic, you're probably familiar with the term "load balancing." But what exactly is load balancing, and why is it so important for the performance and reliability of your online service? In this article, we'll take a deep dive into the world of load balancing and explore the different strategies and techniques that you can use to optimize your website or application's performance.
What is load balancing?
Load balancing is the process of distributing the same information and resources across multiple servers. This lighten's the load for each server as user requests can be spread across a cluster of servers as opposed to being directed to a single one. Load balancing also helps improve reliability and redundancy as if one server fails, requests will simply be redirected towards another working server.
As web applications grow, so does the need for more resources. Load balancing is a straightforward method to help minimize those growing pains and facilitate application scaling.
How does it work?
The way a load balancer works is quite simple:
- The load balancer is, in most cases, a software program that is listening on the port where client requests are made.
- When a request comes in, the load balancer takes that request and forwards it to a backend server which is under acceptable load.
- The backend server then fulfills the request and replies back to the load balancer.
- Finally, the load balancer passes on the reply from the backend server to the client.
This way, the user is never aware of the division of functions between the load balancer and each backend server.
Types of traffic load balancers handle
Load balancers handle four main types of traffic, these include:
- HTTPS - Load balancers handle HTTPS traffic by setting the
X-Forwarded-For,X-Forwarded-Proto, andX-Forwarded-Portheaders to give the backends additional information about the original request. Learn more about how theX-Forward-Forheader works. - HTTP - Load balancers handle HTTP traffic in the same way as HTTPS except with it being encrypted traffic.
- UDP - Certain load balancers support the balancing of protocols such as DNS and syslogd that use UDP.
- TCP - TCP traffic can also be spread across load balancers. Traffic to a database cluster would be a good example of this.
Load balancing techniques
Based on what you want to achieve, this will determine which load balancing technique you should use. The following describes three load balancing techniques.
Round-robin
This is the simplest method of load balancing. Using round-robin, the load balancer simply goes down the list of servers sequentially and passes a request to each one at a time. When the list of servers has reached its end, the load balancer simply restarts the process from the beginning.
This method is straightforward and easy to implement, however, it can pose problems since:
- Not all servers may have the same capacity
- Not all servers may have the same storage
- Not all servers may be up
This results in a less than optimal distribution of client requests since one server may get overloaded before the next, however, it will continue to receive requests regardless.
Two ways around this are to implement weighted round-robin or dynamic round robin. Weighted round-robin involves the site administrator assigning a weight to each server based on its capacity to handle requests. On the other hand, dynamic round robin allows a weight to be assigned dynamically based on real-time statistics of the server's load.
Session-based load balancing
Another common load balancing technique is session-based load balancing. With this strategy, incoming requests are distributed based on the user's session. This means that once a user establishes a connection with a particular server, all subsequent requests from that user will be directed to the same server. This can be especially important for applications that require persistent connections or need to maintain user-specific data, such as online shopping carts or social media platforms.
Session-based load balancing requires a bit more complexity than round-robin load balancing, as the load balancer needs to keep track of which server each user is connected to. However, it can be a very effective way to ensure that each user's experience is consistent and that their data is maintained throughout their session.
IP hash
Based on the vSphere Networking document, IP hash load balancing is described as:
Choose an uplink based on a hash of the source and destination IP addresses of each packet. For non-IP packets, whatever is at those offsets is used to compute the hash.
Put simply, IP hash uses the client's IP address in order to determine which server will receive the request. The largest downfall of this method is that more often than not, the load balancer will not distribute requests to servers equally.
Least connections
This method compares the number of connections for each server in the cluster and based on this will determine which server should process the next request. Each server's capacity limitations are also taken into account when determining which has the smallest amount of connections and which will receive the next request.
Least response time
Using this method, the server with the fewest active connections and the lowest average response times is selected. This ensures speedy delivery of content. To learn more about response times and how to improve them, check out our server response time guide.
Application-based load balancing
Finally, application-based load balancing is a technique that's specifically designed for applications that have complex, multi-tiered architectures. With this strategy, incoming traffic is directed to different servers based on the specific application or service that the user is accessing. For example, if your application has a web server, application server, and database server, application-based load balancing can be used to ensure that traffic is directed to the appropriate server based on the user's request.
Application-based load balancing can be very effective for complex applications, but it does require more advanced configuration and monitoring to ensure that traffic is distributed optimally across all servers.
Benefits of load balancing
There are a variety of benefits that can be realized from implementing a load balancing system. A few of these include:
- Less downtime and greater redundancy for website operators as if a single server goes down, the system will simply reroute traffic to another active server
- A better user experience for visitors as content will most likely load faster for them. The load balancing algorithms mentioned above are made to either distribute the load equally amongst server, which reduces stress and therefore allows servers to respond faster, or delivers content to users from the nearest available server.
- Less stress on a single server. This goes hand-in-hand with the benefit above. Since there is less stress on a single server, not only will visitors receive content faster but there is also less of a chance that the server will be overloaded with requests.
- Improves the scalability of your website or application. As your traffic grows over time, you can add more servers to your pool and adjust your load balancing strategy accordingly to ensure that each server is operating at optimal capacity. This can help ensure that your website or application can continue to handle increased traffic without becoming overloaded or slow.
- It can help improve security by distributing traffic across multiple servers. By using load balancing to spread the load across multiple servers, you can help prevent a single server from becoming a target for malicious traffic or attacks. Additionally, some load balancers offer advanced security features, such as SSL termination and DDoS protection, that can help further improve the security of your website or application.
Of course, there can also be drawbacks to implementing a load balancer. If you're doing it yourself this will add additional complexity to your setup and will take time. Furthermore, whether you're using a software or hardware-based load balancer you will likely need to pay an additional fee for that unless it is already included as a feature in your existing stack.
Choosing the right load balancing solution
Now that you understand the importance of load balancing, how do you choose the right load balancing solution for your website or application? There are several factors to consider.
First, consider the specific needs of your website or application. Do you require session persistence, complex application routing, or advanced security features? Different load balancing strategies may be more or less appropriate depending on the specific requirements of your site.
Second, consider the size and complexity of your infrastructure. If you have a small website or application with only a few servers, a simple round-robin load balancing strategy may be sufficient. However, if you have a complex, multi-tiered architecture with many servers and services, you may require a more advanced application-based load balancing solution.
Finally, consider the cost and complexity of implementing and managing your load balancing solution. Some load balancing solutions may be more expensive or require more advanced technical expertise to implement and manage. Consider the trade-offs between cost, complexity, and functionality when choosing a load balancing solution.
Summary
For scalability purposes, load balancing can be an efficient and straightforward resource distribution method to implement. Various techniques are available to distribute client requests with the goal of mitigating the chance of overloading the server. Implementing a load balancer is an option to consider for scaling a fast growing web application.