Cache Definition and Explanation
Have you ever wondered how your favorite websites and apps load so quickly? How is it possible that they retrieve data and display it so fast? The answer lies in a technology called caching.
In computing, cache is a widely used method for storing information so that it can be later accessed much more quickly. According to Cambridge Dictionary, the cache definition is,
An area or type of computer memory in which information that is often in use can be stored temporarily and got to especially quickly.
This definition, although technically correctly, is slightly lacking given that caching can be applied to a variety of scenarios and it is not just related to computer memory. There are many forms of caching employed in various use-cases. All caching however, aims to achieve the same goal of improving the accessibility time of the particular asset or piece of data you are requesting. This guide should help give you a better understanding of the cache definition and how exactly caching works.
What is cache and how does it work?
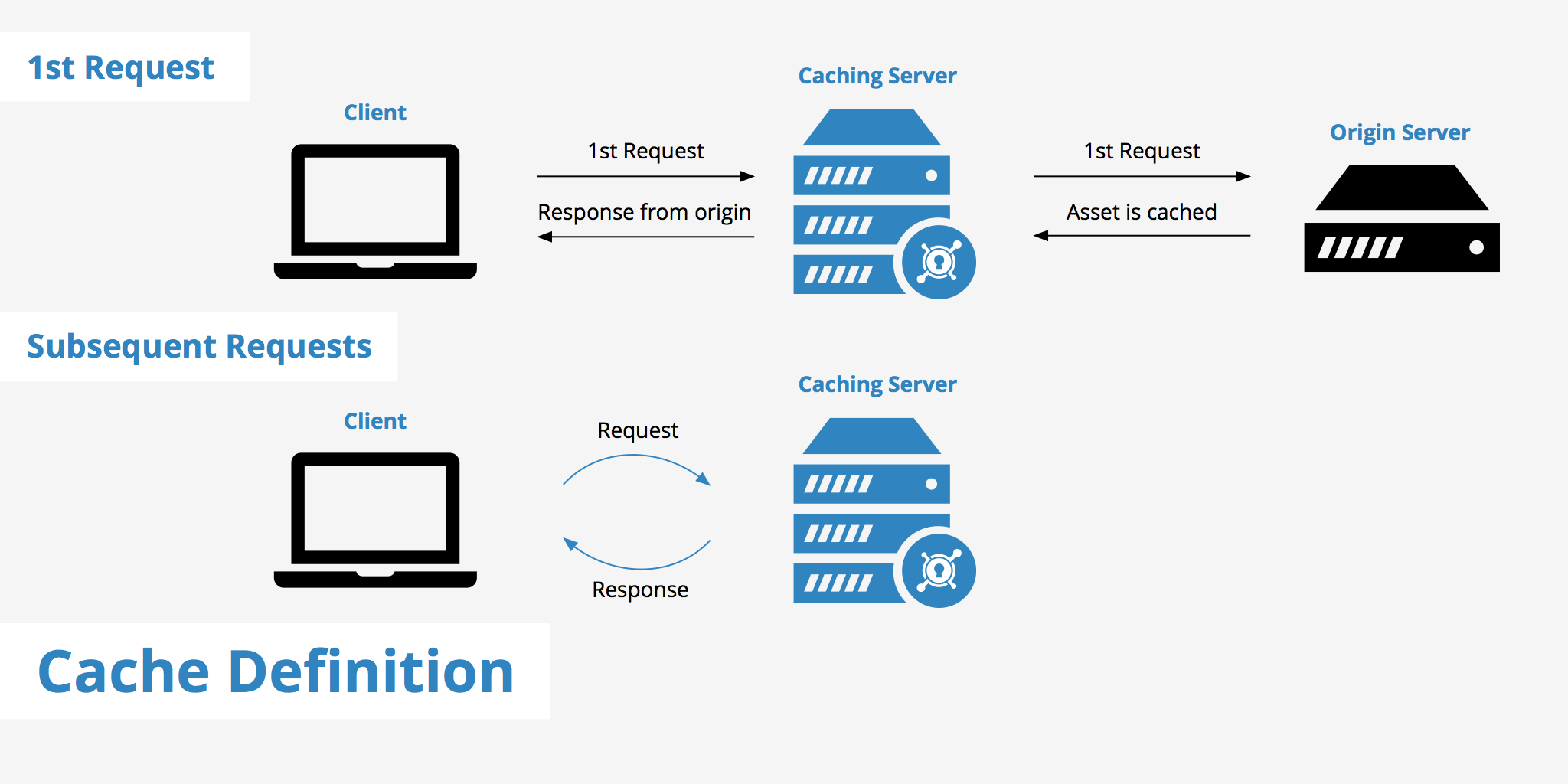
The section above gave a broad definition of what is cache. However, to fully understand the cache definition, we need to understand how it works. When a caching mechanism is in place, it helps improve delivery speed by storing a copy of the asset you requested and later accessing the cached copy instead of the original. To better outline the full process, the following example can be used to better explain how caching works:
- A web page request is made for an asset, such as
https://www.example.com/css/style.css, from the origin server. - The cache is checked first to see if the asset already exists (in the case of a webpage, the cache could pertain to the browser cache, CDN, web proxy, etc).
- If there is not a copy of the requested file stored in cache, this will result in a cache miss and the file will be retrieved from its original source.
- Otherwise, if the file is stored in cache, this results in a cache hit response and the asset is delivered from cache.
- Once the file is cached, it will continue to be delivered from cache until it expires or the cache is cleared / purged.
That is the basic process of how cache works. The above example is in reference to caching a web resource, however, the same process is more or less used for all types of caching mechanisms.
Types of caching
There are various types of caching mechanisms that exist in computing to help speed up different processes. The following section will outline a few popular types of cache and what they are used for.
Cache server
A cache server is a dedicated server used for caching web resources. This type of cache mechanism is used in content delivery networks or web proxies. These servers (called edge servers in CDN terms) can be located in many geographic regions and used to store and deliver data so that the user's request and response does not need to travel as far.
Browser cache
Web browsers store files in their local cache so that they can be accessed faster as they don't need to be downloaded from a server. Leveraging browser cache is an important optimization tactic to use that's also easy to implement on your origin server.
Memory cache
Memory cache is a little different than the two previously mentioned types of cache. This caching mechanism is used in computers to help speed up the delivery of data within an application. The memory cache stores certain parts of data in Static RAM (SRAM) as it is faster to access files using this method rather than accessing them via the hard drive. An example of this could be a music recording program loading certain audio files from the hard drive into SRAM so that they can be quickly accessed.
Disk cache
Disk cache is very similar to memory cache in that is also stores data so that it can be accessed faster when using an application. However, instead of using SRAM, disk cache makes use of conventional RAM. Disk cache stores data that has been recently read as well as adjacent blocks of data that are likely to be accessed soon.
Cache invalidation
One challenge with caching is ensuring that the cached data is still valid. If data in the cache becomes stale or outdated, it can cause problems for users, such as displaying incorrect information. To prevent this, a process called cache invalidation is used.
Cache invalidation is the process of removing data from the cache when it is no longer valid. There are several ways to do this:
Time-based expiration: Data in the cache can be set to expire after a certain amount of time. For example, a cached database query result might be set to expire after 10 minutes.
Event-based invalidation: Data in the cache can be invalidated based on specific events, such as a database update or a file modification.
Manual invalidation: Data in the cache can be manually invalidated by a developer or administrator.
It's important to note that cache invalidation is not always perfect. In some cases, cached data may still be served even when it is outdated. This can be mitigated by setting appropriate expiration times and using event-based invalidation when possible.
Benefits of caching
Caching provides several benefits, including:
Improved performance: Caching reduces the amount of time it takes to retrieve data, which improves the performance of websites and applications.
Reduced server load: When data is cached, servers don't have to retrieve it from its original source as often, which reduces the load on the server.
Reduced bandwidth usage: Caching reduces the amount of data that needs to be transferred between the server and the client, which reduces bandwidth usage.
Improved user experience: When websites and applications load quickly, users are more likely to have a positive experience.
Common caching problems
While caching can improve performance, it can also cause problems if not implemented correctly. Here are some common caching problems to be aware of:
Cache stampede: When a large number of requests come in at the same time, and the cache is empty, all the requests may try to retrieve the data from the original source at once, causing a spike in server load.
Stale data: If the cache is not invalidated properly, stale data may be served, causing incorrect information to be displayed to users.
Inconsistent data: In some cases, cached data may be inconsistent across different servers or clients, causing unexpected behavior.
Cache pollution: When the cache is filled with data that is rarely accessed, it can cause important data to be evicted prematurely.
Other important considerations for caching
In addition to the topics covered in the previous chapters, there are a few other important considerations to keep in mind when working with caching:
Cache size: The size of the cache is an important factor to consider. If the cache is too small, it may not provide a significant performance boost. If it's too large, it can lead to memory usage issues.
Cache placement: Caching can be done at various levels of a system, including the client, the application server, and the database server. The placement of the cache can affect its effectiveness and the level of control over the cached data.
Cache security: Cached data can potentially be accessed by unauthorized users if proper security measures are not taken. It's important to ensure that cached data is secure and that sensitive information is not cached.
Cache warming: In some cases, it may be beneficial to warm up the cache by preloading commonly accessed data before it's actually needed. This can help reduce cache miss rates and improve overall performance.
Cache partitioning: If multiple servers or clients are accessing the same cache, it may be necessary to partition the cache to avoid conflicts and ensure consistent data.
Overall, caching is a complex topic that requires careful consideration and planning to implement effectively. By understanding the various factors involved, developers and administrators can use caching to improve the performance of their systems and provide a better user experience.
Difference between cache definition and buffer definition
Although both cache and buffers do share certain similarities, there are a couple key differences that set them apart. According to Wikipedia, the definition of a buffer is
A temporary memory location that is traditionally used because CPU instructions cannot directly address data stored in peripheral devices.
Buffers are meant to store file metadata (e.g. what's in certain directions, user permissions, etc) while a cache only contains the content of the file itself. As mentioned in the definition, buffers are able to serve as an intermediary for devices to communicate between one another that are incapable of direct transfer. Therefore both buffers and cache are meant to store particular data, however, it is the type of data stored as well as the purpose of storing such data that differs.
Summary
Now that we've shed some light on the cache definition as well as explained what is cache exactly and how it is used, hopefully you now have a better idea of just how useful caching is. In today's technological environment speed is a very important factor. Being able to access data quickly is vital. Although different forms of caching exist, they all reach for the same goal - to store a copy of data somewhere that is more readily available upon subsequent requests.